Thursday, December 15, 2022
Tuesday, December 6, 2022
If you are newbie to AWS Glue its really difficult to run the Crawlers without these failures , Below are basic steps you need to make sure done before running the Crawler



- AWS IAM Role and Privileges
- S3 Endpoint
1.AWS IAM Role and Policies
We have to atleast attach below policies in IAM Role

2.S3 Endpoint
Most of the time you will get below error ,
VPC S3 endpoint validation failed for SubnetId: subnet-0e0b8e2ad1b85d036. VPC: vpc-01bdc81e45566a823. Reason: Could not find S3 endpoint or NAT gateway for SubnetId: subnet-0e0b8e2ad1b85d036 in Vpc vpc-01bdc81e45566a823 (Service: AWSGlueJobExecutor; Status Code: 400; Error Code: InvalidInputException; Request ID: 0495f22f-a7b5-4f74-8691-7de8a6a47b42; Proxy: null)

To fix this error , you need understand the issue first . Its saying
Create Endpoints for S3 not for Glue , Some worst cases people create Nat Gateway and they loss huge money for simple thing . So you have to create S3 Endpoint Gateway as like below ,

Once we created your job will run like flight :)
Always customer prefers cost less solutions to run the business . To help them their business and the requirements we also needs to provide efficient solutions
Some cases cloud vendors provides good solutions for analytics load but cost will be very high , most of the time we don't want to recommend that but we need to do
Like that one of the solution in AWS , its cost much but works much faster like anything
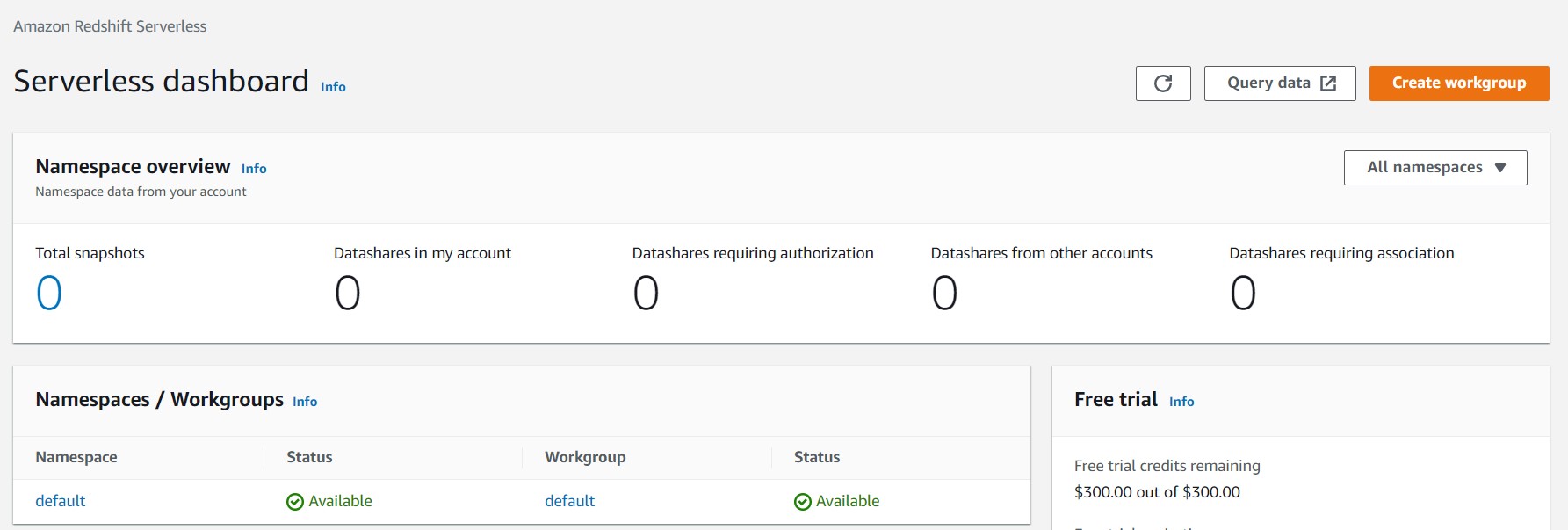
We are talking about Amazon Redshift Solutions only , So recently they have launched Amazon Redshift Serverless solutions for few regions .
Whatever new comes , before customer catches the features we need to find and deliver the best approach to them . So ,
What is Amazon Redshift Serverless ?
Amazon Redshift Serverless automatically provisions data warehouse capacity and intelligently scales the underlying resources. Amazon Redshift Serverless adjusts capacity in seconds to deliver consistently high performance and simplified operations for even the most demanding and volatile workloads.
With Amazon Redshift Serverless, you can benefit from the following features:
- Access and analyze data without the need to set up, tune, and manage Amazon Redshift provisioned clusters
- Use the superior Amazon Redshift SQL capabilities, industry-leading performance, and data-lake integration to seamlessly query across a data warehouse, a data lake, and operational data sources
- Deliver consistently high performance and simplified operations for the most demanding and volatile workloads with intelligent and automatic scaling
- Use workgroups and namespaces to organize compute resources and data with granular cost controls
- Pay only when the data warehouse is in use
So , Overall no need of human interventions in the Redshift Serverless
Everything is Fine , How to we migrate and sync Amazon RDS / EC2 Postgres / Aurora Postgres to utilize this Redshift Serverless
What are the options available to migrate and Sync ?
- DMS - Still Redshift Target is not available to migrate the Data
- Export/Import - Yes we can perform , how to handle zero downtime migration . Syncing real-time data is not possible
- AWS Glue - Its Good Option , We can migrate and Sync real-time data from RDS to Redshift Serverless
Lets start sample data migrate and sync into Amazon Redshift Serverless ,
Environment Setup Go Through ,
- RDS PostgreSQL
- AWS Glue
- Amazon Redshift Serverless
- VPC S3 Endpoint
- IAM Role
RDS PostgreSQL :

Amazon Redshift Serverless :
VPC S3 Endpoint :

IAM Role :

Once Environment is completed , we can start adding connections and jobs in AWS Glue
How to add connections in AWS Glue ,
In AWS Glue Console --> Click Connections --> Create Connections



Create source and target databases ,

For testing sample schema and data inserted into RDS PostgreSQL before creating the crawler
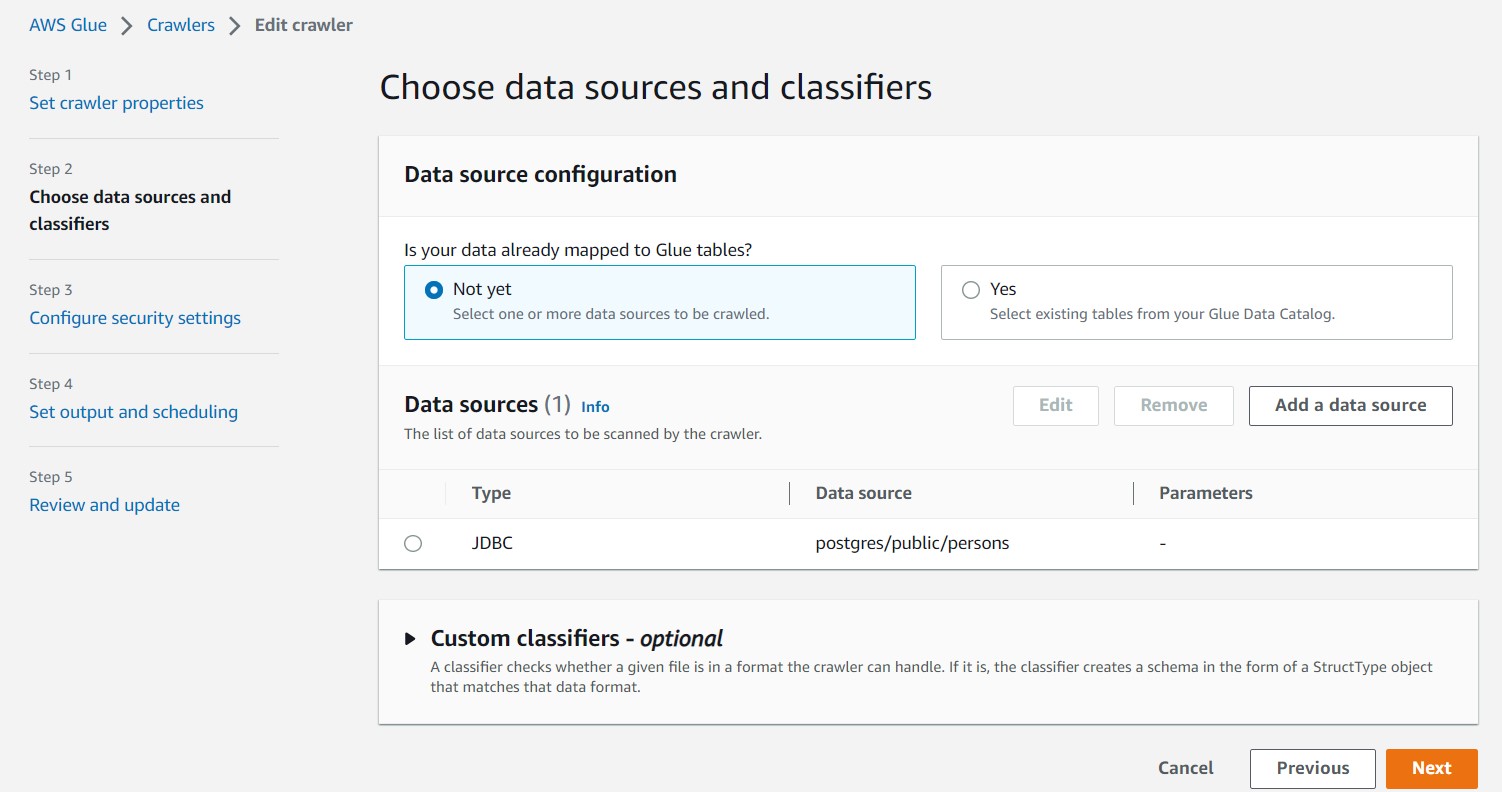
Lets start to create separate crawlers for Source and Target to update catalog ,
Below data source is mapped to RDS PostgreSQL
Also required policies updated role needs to attached ,

Choose appropriate databases for crawler , below is the for source

Below is the for Target ,

Once its completed , we have already deployed sample schema scripts in both side to transfer the data . Lets run the crawler and check it

So both source and target tables are updated

Lets Create Glue Job in AWS Console ,


After all , Lets schedule the job every 5 Minutes and sync the data


So Quickly we can migrate and save our cost
Any Troubles and issues Please contact me immediately !!!
Thursday, November 10, 2022

Sunday, August 28, 2022
Three hours of long running pipeline is reduced to run in 35 Minutes when we given right kind of top bottom optimization like our Body !!!
Yes Sometimes if we give proper core and cross workouts you can run 10km in 55 Minutes !!!
Its happened to me But Not Now 😆😆😆
Oh Oh we are away from Data ground !!! Lets Move into Azure Synapse tunning,
In the starting phase every piece of code and pipeline process was really trouble us to optimize it , whatever we do on tunning it will run as same time
Waited long time until each process to complete as its running 3 hours !!!
But Reecha blog helped something to start with basic check and given some hope to fine tune it
Remember below piece of monitoring code always help us to too dig more
--Check Long Running Query in Azure Synapse
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE status not in ('Completed','Failed','Cancelled')
AND session_id <> session_id()
ORDER BY submit_time DESC;--Find the distributed query plan steps for long running query SELECT * FROM sys.dm_pdw_request_steps WHERE request_id = 'xxxxxx' ORDER BY step_index; ***Replace your request_id from first query resultSample Running Query :

Initially we thought data volume is huge , so we are expecting this much delay on complete . But distributed query Plans are given more finishing time for each queries in Azure Synapse
We will go step by step process of tunning ,
Multiple ways we can see the Execution plan of your Azure Synapse Queries
- Using Azure Console --> Click you Dedicated Pool --> Click Query Activity --> Each Queries you have Query Plans

2.Using SSMS , you can run below query and get your explain plan in XML Format
EXPLAIN select * from dbo_datablogs.vw_fact_transferdata (nolock)

So ,We have figured out the execution plan and further need to fix below things to make it faster
We need to reduce data movement operations ( Shuffle Move , Trim Move , Partition Move ) and needs to have proper indexing on your business tables
Based on your data distribution on tables and indexing , queries will be executed on SQL Pool . We need to distribute the tables accordingly . So Major part of the tunning on table level only
Once we done that in proper way we have achieved your milestone ,
How to we distribute table in Azure Synapse ?
Two types of distribution is available in Azure Synapse . Round Robin and Hash Distribution
Round Robin Distribution
- By Default , If you create table it will create in Round Robin Distribution
- Table rows are distributed in all distribution
- Main purpose of this table to improve loading speed we can use round robin distribution
- If your table is just junk or doesn't have proper any constraints and keys use round robin distribution
CREATE TABLE [dbo_datablogs].[ControlTable_blogs](
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
[SourceObjectSettings] [nvarchar](max) NULL)
WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN )
Hash Distribution
- If your table is having frequent DML operations ( Insert , Update , Delete ) use hash distribution
- It will increase performance 200% of your queries
- It will distribute the data to nodes based on your distributed column
CREATE TABLE [dbo_datablogs].[ControlTable_blogs](
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
[SourceObjectSettings] [nvarchar](max) NULL)
WITH ( HEAP, DISTRIBUTION = HASH(Id))
Replicate
This is another way to storing the table in SQL Pool
- Full copy of the table will be available in all distribution to avoid data movement
- Table is having less size use replicate option
CREATE TABLE [dbo_datablogs].[ControlTable_blogs](
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
[SourceObjectSettings] [nvarchar](max) NULL)
WITH ( HEAP, DISTRIBUTION = REPLICATE )
Thumb of Rules of Creating tables
First Level : Find the absolute unique column or else use partial unique column for creating table as Hash Distribution
Second Level : If your table doesn't have proper unique columns , try to create the table with used columns in Join , Group By , Distinct , Over and Having Clauses on Procedures or Select Clauses
Lets examine First Level ,
When creating the table with Round Robin and created table with below script ,
CREATE TABLE dbt_datablogs.fact_transferdata
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM dbt_datablogs.vw_fact_transferdata
Its taken 28 Minutes to complete

So we figured out good candidate key and created table with below script
CREATE TABLE dbt_datablogs.fact_transferdata
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(tranferaddressid)
)
AS SELECT * FROM dbt_datablogs.vw_fact_transferdata
Its taken 4 Minutes to complete

We will see the huge difference when creating proper keys
Lets examine Second Level ,
When we don't have proper keys , based on your business logics or select clause join conditions we can try to evaluate with multiple columns and create proper hash function to improve performance
Lets do the smaller table tunning on this blog , you can try the same in your own environments ,
Below table is small but its having shuffle move and its delaying the process 11 Minutes ,




Then based on shuffle columns , add the proper hash function and recreate the table
CREATE TABLE dbt_datablogs.fact_memberinfo
WITH
(
Heap,
DISTRIBUTION = HASH(infoid)
)
AS SELECT * FROM dbt_datablogs.vw_memberinfo
Once created the table again examined the Execution plan for the same statement and process is finished with in a seconds

This is not an end , Also we have tunned few things on Data Factory and Azure Synapse Workload Management to get expected performance , we will see further on next blog
To learn more in-depth , Please use below references from Microsoft Site as well
References :
1.Cheat Sheet - https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet?view=azure-sqldw-latest
2.Distributed Tables - https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
3.Replicated Tables - https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-guidance-for-replicated-tables