
MongoDB 8.0 Production Deployment on Azure AKS with Internal LoadBalancer + SRV Setup
Got free Azure credits to learn and explore Azure AKS with MongoDB. Tried my best to gain hands-on experience and learn as much as possible ...
Read More
Got free Azure credits to learn and explore Azure AKS with MongoDB. Tried my best to gain hands-on experience and learn as much as possible ...
Read More
Why SQL Server Licensing Matters Choosing the right SQL Server license helps organizations: Optimize licensing cost Avoid compliance i...
Read MoreLets deep into active active high availability solution on PostgreSQL Detailed Session on the Live Recording Session https://www.youtube.c...
Read More
We love MongoDB for extraordinary features as per business perspective Lets come to our Blog Discussion , Only in PaaS Environments we have...
Read More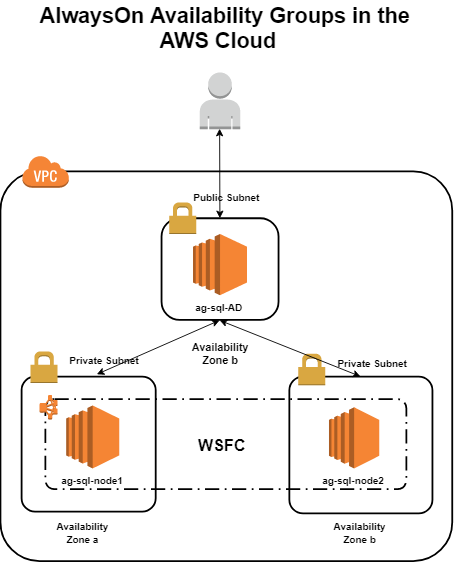
Microsoft gives HA features like a charm . Lower to higher deployment costs its giving many features as per business requirements . Replicat...
Read More
It is easy to migrate the MySQL databases from one cloud provider to another cloud provider , but without downtime is little difficult to m...
Read More
MongoDB supports horizontal scaling of the data with the help of the shared key. Shared key selection should be good and poor shared key spl...
Read More