Thursday, November 10, 2022

Sunday, August 28, 2022
Three hours of long running pipeline is reduced to run in 35 Minutes when we given right kind of top bottom optimization like our Body !!!
Yes Sometimes if we give proper core and cross workouts you can run 10km in 55 Minutes !!!
Its happened to me But Not Now 😆😆😆
Oh Oh we are away from Data ground !!! Lets Move into Azure Synapse tunning,
In the starting phase every piece of code and pipeline process was really trouble us to optimize it , whatever we do on tunning it will run as same time
Waited long time until each process to complete as its running 3 hours !!!
But Reecha blog helped something to start with basic check and given some hope to fine tune it
Remember below piece of monitoring code always help us to too dig more
--Check Long Running Query in Azure Synapse
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE status not in ('Completed','Failed','Cancelled')
AND session_id <> session_id()
ORDER BY submit_time DESC;--Find the distributed query plan steps for long running query SELECT * FROM sys.dm_pdw_request_steps WHERE request_id = 'xxxxxx' ORDER BY step_index; ***Replace your request_id from first query resultSample Running Query :

Initially we thought data volume is huge , so we are expecting this much delay on complete . But distributed query Plans are given more finishing time for each queries in Azure Synapse
We will go step by step process of tunning ,
Multiple ways we can see the Execution plan of your Azure Synapse Queries
- Using Azure Console --> Click you Dedicated Pool --> Click Query Activity --> Each Queries you have Query Plans

2.Using SSMS , you can run below query and get your explain plan in XML Format
EXPLAIN select * from dbo_datablogs.vw_fact_transferdata (nolock)

So ,We have figured out the execution plan and further need to fix below things to make it faster
We need to reduce data movement operations ( Shuffle Move , Trim Move , Partition Move ) and needs to have proper indexing on your business tables
Based on your data distribution on tables and indexing , queries will be executed on SQL Pool . We need to distribute the tables accordingly . So Major part of the tunning on table level only
Once we done that in proper way we have achieved your milestone ,
How to we distribute table in Azure Synapse ?
Two types of distribution is available in Azure Synapse . Round Robin and Hash Distribution
Round Robin Distribution
- By Default , If you create table it will create in Round Robin Distribution
- Table rows are distributed in all distribution
- Main purpose of this table to improve loading speed we can use round robin distribution
- If your table is just junk or doesn't have proper any constraints and keys use round robin distribution
CREATE TABLE [dbo_datablogs].[ControlTable_blogs](
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
[SourceObjectSettings] [nvarchar](max) NULL)
WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN )
Hash Distribution
- If your table is having frequent DML operations ( Insert , Update , Delete ) use hash distribution
- It will increase performance 200% of your queries
- It will distribute the data to nodes based on your distributed column
CREATE TABLE [dbo_datablogs].[ControlTable_blogs](
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
[SourceObjectSettings] [nvarchar](max) NULL)
WITH ( HEAP, DISTRIBUTION = HASH(Id))
Replicate
This is another way to storing the table in SQL Pool
- Full copy of the table will be available in all distribution to avoid data movement
- Table is having less size use replicate option
CREATE TABLE [dbo_datablogs].[ControlTable_blogs](
[Id] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
[SourceObjectSettings] [nvarchar](max) NULL)
WITH ( HEAP, DISTRIBUTION = REPLICATE )
Thumb of Rules of Creating tables
First Level : Find the absolute unique column or else use partial unique column for creating table as Hash Distribution
Second Level : If your table doesn't have proper unique columns , try to create the table with used columns in Join , Group By , Distinct , Over and Having Clauses on Procedures or Select Clauses
Lets examine First Level ,
When creating the table with Round Robin and created table with below script ,
CREATE TABLE dbt_datablogs.fact_transferdata
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM dbt_datablogs.vw_fact_transferdata
Its taken 28 Minutes to complete

So we figured out good candidate key and created table with below script
CREATE TABLE dbt_datablogs.fact_transferdata
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(tranferaddressid)
)
AS SELECT * FROM dbt_datablogs.vw_fact_transferdata
Its taken 4 Minutes to complete

We will see the huge difference when creating proper keys
Lets examine Second Level ,
When we don't have proper keys , based on your business logics or select clause join conditions we can try to evaluate with multiple columns and create proper hash function to improve performance
Lets do the smaller table tunning on this blog , you can try the same in your own environments ,
Below table is small but its having shuffle move and its delaying the process 11 Minutes ,




Then based on shuffle columns , add the proper hash function and recreate the table
CREATE TABLE dbt_datablogs.fact_memberinfo
WITH
(
Heap,
DISTRIBUTION = HASH(infoid)
)
AS SELECT * FROM dbt_datablogs.vw_memberinfo
Once created the table again examined the Execution plan for the same statement and process is finished with in a seconds

This is not an end , Also we have tunned few things on Data Factory and Azure Synapse Workload Management to get expected performance , we will see further on next blog
To learn more in-depth , Please use below references from Microsoft Site as well
References :
1.Cheat Sheet - https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet?view=azure-sqldw-latest
2.Distributed Tables - https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
3.Replicated Tables - https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-guidance-for-replicated-tables
Thursday, August 11, 2022
Oooooouch !!! I have deleted critical data in the ledger table !!!
When we ran delete or drop Script on any database without double check , Its Really big problem for the end users !!! Also you wont sleep 😁😁😁
If you have GODDBA , you are saved millions dollars of your data also your valuable customers .
Oh Great 😀😀😀 How we can achieve that ?
In SQL Server Multiple Database Backup Methods are available to tackle that ,
If SQL Server database is in full recovery model we can take transaction log backups on every hour/Minute/Seconds into local or remote drives .
So, Yes am taking Log Backup 😕😕😕 How to we restore particular time ?
Using with transaction logs we can bring back the data as much as you want depends on your log backup strategy .
To achieve that here is the automated point in time restore script for your valuable environment ,
Scripts are available in https://github.com/selvackp/SQLServerPointInTimeRestore.git
So finally you have saved your millions dollars worth of data in 10 Minutes !!!
USE master GO DECLARE @DatabaseOLDName sysname = 'test', @DatabaseNewName sysname = 'test1', @PrimaryDataFileName sysname = 'test', @SecDataFileName sysname = NULL, @DatabaseLogFileName sysname = 'test_log', @PrimaryDataFileCreatePath sysname = 'D:\MISC\Bkp\testdata.mdf', @SecDataFileCreatePath sysname = NULL, @SecDataFileCreatePath1 sysname = NULL, @DatabaseLogFileCreatePath sysname = 'D:\MISC\Bkp\test_log.ldf', @PITRDateTime datetime = '2022-08-11T20:44:11'; DECLARE @command nvarchar(MAX), @OldPhysicalPathName nvarchar(MAX), @FullBackupDateTime datetime, @DiffBackupDateTime datetime, @LogBackupDateTime datetime, @message nvarchar(MAX); SET @command = N'RESTORE DATABASE @DatabaseNewName FROM DISK = @OldPhysicalPathName WITH FILE = 1, NORECOVERY, NOUNLOAD, REPLACE, STATS = 5, STOPAT = @PITRDateTime, MOVE N''' + @PrimaryDataFileName + N''' TO N''' + @PrimaryDataFileCreatePath + N''',' + COALESCE(' MOVE N''' + @SecDataFileName + ''' TO N''' + @SecDataFileCreatePath + ''',', '') + N' MOVE N''' + @DatabaseLogFileName + N''' TO N''' + @DatabaseLogFileCreatePath + N''';'; SELECT TOP (1) @OldPhysicalPathName = bmf.physical_device_name,@FullBackupDateTime = bs.backup_start_date FROM msdb.dbo.backupset AS bs INNER JOIN msdb.dbo.backupmediafamily AS bmf ON bmf.media_set_id = bs.media_set_id WHERE bs.database_name = @DatabaseOLDName AND bs.type= 'D' AND bs.backup_start_date < @PITRDateTime ORDER BY bs.backup_start_date DESC; SET @message = N'Starting restore of full backup file '+ @OldPhysicalPathName + N', taken ' + CONVERT(nvarchar(30), @FullBackupDateTime, 120); RAISERROR(@message, 0, 1) WITH NOWAIT; EXEC sys.sp_executesql @command, N'@DatabaseNewName sysname, @OldPhysicalPathName nvarchar(260), @PITRDateTime datetime', @DatabaseNewName, @OldPhysicalPathName, @PITRDateTime; SET @command = N'RESTORE DATABASE @DatabaseNewName FROM DISK = @OldPhysicalPathName WITH FILE = 1, NORECOVERY, NOUNLOAD, REPLACE, STATS = 5, STOPAT = @PITRDateTime;'; SELECT TOP (1) @OldPhysicalPathName = bmf.physical_device_name,@DiffBackupDateTime = bs.backup_start_date FROM msdb.dbo.backupset AS bs INNER JOIN msdb.dbo.backupmediafamily AS bmf ON bmf.media_set_id = bs.media_set_id WHERE bs.database_name = @DatabaseOLDName AND bs.type = 'I' AND bs.backup_start_date >= @FullBackupDateTime AND bs.backup_start_date< @PITRDateTime ORDER BY bs.backup_start_date DESC; IF @@ROWCOUNT > 0 BEGIN; SET @message = N'Starting restore of differential backup file ' + @OldPhysicalPathName + N', taken ' + CONVERT(nvarchar(30), @DiffBackupDateTime, 120); RAISERROR(@message, 0, 1) WITH NOWAIT; EXEC sys.sp_executesql @command, N'@DatabaseNewName sysname, @OldPhysicalPathName nvarchar(260), @PITRDateTime datetime', @DatabaseNewName, @OldPhysicalPathName, @PITRDateTime; END; SET @command = N'RESTORE LOG @DatabaseNewName FROM DISK = @OldPhysicalPathName WITH FILE = 1, NORECOVERY, NOUNLOAD, REPLACE, STATS = 5, STOPAT = @PITRDateTime;'; DECLARE c CURSOR LOCAL FAST_FORWARD READ_ONLY TYPE_WARNING FOR SELECT bmf.physical_device_name, bs.backup_start_date FROM msdb.dbo.backupset AS bs INNER JOIN msdb.dbo.backupmediafamily AS bmf ON bmf.media_set_id = bs.media_set_id WHERE bs.database_name = @DatabaseOLDName AND bs.type = 'L' AND bs.backup_start_date >= COALESCE(@DiffBackupDateTime, @FullBackupDateTime) ORDER BY bs.backup_start_date ASC; OPEN c; FETCH NEXT FROM c INTO @OldPhysicalPathName, @LogBackupDateTime; WHILE @@FETCH_STATUS = 0 BEGIN; SET @message = N'Starting restore of log backup file ' + @OldPhysicalPathName + N', taken ' + CONVERT(nvarchar(30), @LogBackupDateTime, 120); RAISERROR(@message, 0, 1) WITH NOWAIT; EXEC sys.sp_executesql @command, N'@DatabaseNewName sysname, @OldPhysicalPathName nvarchar(260), @PITRDateTime datetime', @DatabaseNewName, @OldPhysicalPathName, @PITRDateTime; IF @LogBackupDateTime >= @PITRDateTime BREAK; FETCH NEXT FROM c INTO @OldPhysicalPathName, @LogBackupDateTime; END; CLOSE c; DEALLOCATE c; SET @command = N'RESTORE DATABASE @DatabaseNewName WITH RECOVERY;'; RAISERROR('Starting recovery', 0, 1) WITH NOWAIT; EXEC sys.sp_executesql @command, N'@DatabaseNewName sysname, @OldPhysicalPathName nvarchar(260), @PITRDateTime datetime', @DatabaseNewName, @OldPhysicalPathName, @PITRDateTime; GO
Wednesday, March 30, 2022
We love MongoDB for extraordinary features as per business perspective
Lets come to our Blog Discussion , Only in PaaS Environments we have features like DNS endpoints for database easily connect with primary or secondary at any single point of failure
Mongo Atlas Providing all the features but small scale customers still using MongoDB with Virtual Machines or EC2 Instances . To handle point of failures in primary we can use DNS Seed List Connection Format in mongoDB . We will discuss in detail how to we configure this in AWS Cloud
What is seed list ?
Seed list can be list of hosts and ports in DNS Entries . Using DNS we can configure available mongoDB servers in under one hood . When client connects to an common DNS , its also knows replica set members available in seed list . Single SRV identifies all the nodes associated with the cluster . Like Below ,
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false" Percona Server for MongoDB shell version v4.4.13-13 connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=false

Environment Setup :
For Testing Purpose , We have launched 3 Private Subnet Servers and 1 Public Subnet Server to use like Bastion . Create One Private Hosted Zone for DNS and Installed Percona Server for MongoDB 4.4.13 then configured Replication in it
AWS EC2 Servers ,

Route 53 Hosted Zone ,

Creating A Records :
We have launched private subnet instances , so we required to create A Records for private IP's . If Public IPv4 DNS available we can create CNAME Records
A Records Created for db1 server ,
Inside the datamongo.com hosted Zone , Just Click Create Record

Same like we need to create A Records for other two nodes

Verify the A Records ,
root@ip-172-31-95-215:~# dig db1.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db1.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 13639 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db1.datamongo.com. IN A ;; ANSWER SECTION: db1.datamongo.com. 10 IN A 172.31.85.180 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 11:58:09 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~# dig db2.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db2.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9496 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db2.datamongo.com. IN A ;; ANSWER SECTION: db2.datamongo.com. 300 IN A 172.31.83.127 ;; Query time: 3 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 12:06:28 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~# dig db3.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db3.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46401 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db3.datamongo.com. IN A ;; ANSWER SECTION: db3.datamongo.com. 300 IN A 172.31.86.8 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 12:06:33 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~#
Creating SRV and TXT Records :
As like Atlas , Once we have the A Records for MongoDB Nodes , we can able to create SRV Records
Again Inside the datamongo.com hosted Zone , Just Click Create Record

Once its created , again click create record and create TXT records


Reading SRV and TXT Records :
We can use nslookup and verify the configured DNS Seeding ,
root@ip-172-31-95-215:~# nslookup > set type=SRV > _mongodb._tcp.db.datamongo.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: _mongodb._tcp.db.datamongo.com service = 0 0 27717 db2.datamongo.com. _mongodb._tcp.db.datamongo.com service = 0 0 27717 db3.datamongo.com. _mongodb._tcp.db.datamongo.com service = 0 0 27717 db1.datamongo.com. Authoritative answers can be found from: > set type=TXT > db.datamongo.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: db.datamongo.com text = "authSource=admin&replicaSet=db-replication" Authoritative answers can be found from:
Verify Connectivity :
Its all done , We can verify the connectivity with DNS Seed List Connection format ,
By Default , it will connect with ssl true , but we have configured mongodb without SSL . If you required to configure with SSL please refer our blog and configure DNS Seeding with help of this blog
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false"
Percona Server for MongoDB shell version v4.4.13-13
connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=false
Implicit session: session { "id" : UUID("ee74effc-92c7-4189-9e97-017afb4b4ad4") }
Percona Server for MongoDB server version: v4.4.13-13
---
The server generated these startup warnings when booting:
2022-03-29T11:32:47.133+00:00: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine. See http://dochub.mongodb.org/core/prodnotes-filesystem
---
db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;
172.31.83.127:27717
db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;
PRIMARY
db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).name;
172.31.85.180:27717
db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).stateStr;
SECONDARYCurrently 172.31.83.127 is the primary server and 172.31.85.180 is secondary , to test connection we have stopped the primary server (172.31.83.127) in AWS console
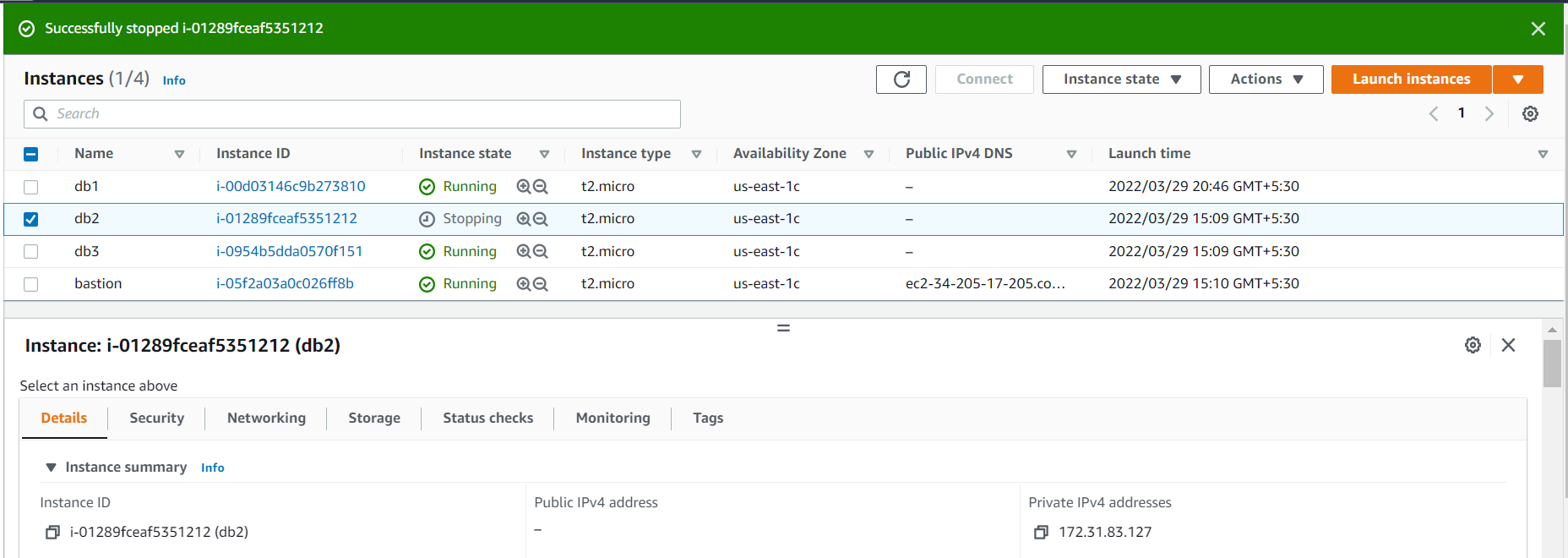
after stopping primary server (172.31.83.127) , mongodb failover happened to to 172.31.85.180 . Its verified without disconnecting the mongo shell
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false"Percona Server for MongoDB shell version v4.4.13-13connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=falseImplicit session: session { "id" : UUID("ee74effc-92c7-4189-9e97-017afb4b4ad4") }Percona Server for MongoDB server version: v4.4.13-13---The server generated these startup warnings when booting:2022-03-29T11:32:47.133+00:00: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine. See http://dochub.mongodb.org/core/prodnotes-filesystem---db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;172.31.83.127:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;PRIMARYdb-replication:PRIMARY> rs.status().members.find(r=>r.state===2).name;172.31.85.180:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).stateStr;SECONDARYdb-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;172.31.85.180:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;PRIMARY
Its working as expected and we have no worries if anything happens on mongoDB primary node in Cloud IaaS as Well !!!
Please contact us if any queries and concerns , we are always happy to help !!!
Friday, March 18, 2022
We have upgraded Oracle Apex in the previous blog and next have to plan for below things
- Apex static images update for upgraded version
- ORDS Upgrade to stable version

Prerequisites
- Downloads the upgraded apex version in oracle RDS ( Apex 21.1.2 )
- Download latest stable version of ORDS 19.4
- Make sure you have already configured Oracle Client 19C and Java 1.8 is installed
Apex Static Image Upgrade :
Before upgrade apex images , we will receive below error while login apex workspace page

- Rename the existing apex folder from D:\apex to D:\apex_5.1.4
- Unzip the apex_21.1_en.zip folder into apex folder
- Go to apex utilities folder
- Stop the ORDS running service
Connect Oracle 19C in SQL Plus
C:\Windows\system>D:
D:\>cd apex
D:\apex>cd utilities
D:\apex\utilities>
D:\apex\utilities>sqlplus dataadmin@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dataadmin.cwt1dgu2zxag.ap-southeast-1.rds.amazonaws.com)(PORT=1521))(CONNECT_DATA=(SID=ORCL)))
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
Enter Password:
SQL> @reset_image_prefix.sql
Enter the Application Express image prefix [/i/] https://static.oracle.com/cdn/apex/21.1.2/
...Changing Application Express image prefix
NEW_IMAGE_PREFIX
------------------------------------------
https://static.oracle.com/cdn/apex/21.1.2/
PL/SQL procedure successfully completed.
...Recreate APEX global
PL/SQL procedure successfully completed.
Commit complete.
Image Prefix update complete
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.13.0.0.0
D:\apex\utilities>
Once its completed , we will able to browse the apex pages without any issues
ORDS Upgrade Paths
Step 1 :
Rename existing ords folder as ords_3.0.13 . As mentioned in prerequisites , unzip the downloaded ords-19.4.6.142.1859 into ords folder
Step 2 :
Copy the D:/apex/images folder into D:/ords/
Step 3:
Uninstall the existing ORDS version from Oracle RDS ,
D:\ords>java -jar ords.war uninstall Specify the database connection type to use. Enter number for [1] Basic [2] TNS [3] Custom URL [1]: Enter the name of the database server [localhost]:dataadmin.cwt1dgu2zxag.ap-southeast-1.rds.amazonaws.com Enter the database listen port [1521]: Enter 1 to specify the database service name, or 2 to specify the database SID [1]: Enter the database service name:ORCL Requires to login with administrator privileges to verify Oracle REST Data Services schema. Enter the administrator username:dataadmin Enter the database password for dataadmin: Confirm password: Connecting to database user: dataadmin url: jdbc:oracle:thin:@//dataadmin.cwt1dgu2zxag.ap-southeast-1.rds.amazonaws.com:1521/ORCL Retrieving information. Uninstalling Oracle REST Data Services ... Log file written to C:\Users\datablogsadmin\ords_uninstall_core_2022-03-16_133300_00152.log Completed uninstall for Oracle REST Data Services. Elapsed time: 00:00:07.840Step 4 :
Set Config Directory
java -jar ords.war configdir D:\config
Step 5 :
Update passwords and unlock below accounts in Oracle RDS
- APEX_PUBLIC_USER
- APEX_LISTENER
- APEX_REST_PUBLIC_USER
Connect Oracle 19C in SQL Plus
D:\apex\utilities>sqlplus dataadmin@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dataadmin.cwt1dgu2zxag.ap-southeast-1.rds.amazonaws.com)(PORT=1521))(CONNECT_DATA=(SID=ORCL)))
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
Enter Password:
SQL>alter user APEX_PUBLIC_USER account unlock identified by Admin123;
SQL>exec rdsadmin.rdsadmin_run_apex_rest_config('Admin123','Admin123');
SQL>ALTER USER APEX_REST_PUBLIC_USER account unlock IDENTIFIED BY Admin123;
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('DBA_OBJECTS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('DBA_ROLE_PRIVS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('DBA_TAB_COLUMNS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_CONS_COLUMNS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_CONSTRAINTS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_OBJECTS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_PROCEDURES', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_TAB_COLUMNS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_TABLES', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('USER_VIEWS', 'DATAADMIN', 'SELECT', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('WPIUTL', 'DATAADMIN', 'EXECUTE', true);
SQL>exec rdsadmin.rdsadmin_util.grant_sys_object('DBMS_SESSION', 'DATAADMIN', 'EXECUTE', true);
SQL>EXEC rdsadmin.rdsadmin_util.grant_apex_admin_role;
SQL>grant APEX_ADMINISTRATOR_ROLE to DATAADMIN;
Once its executed , proceed the ORDS InstallationInstall the required database naming configuration setup for ORDS , By default it will install as apex
D:\ords>java -jar ords.war setup --database dataadmin Specify the database connection type to use. Enter number for [1] Basic [2] TNS [3] Custom URL [1]: Enter the name of the database server [localhost]:dataadmin.cwt1dgu2zxag.ap-southeast-1.rds.amazonaws.com Enter the database listen port [1521]: Enter 1 to specify the database service name, or 2 to specify the database SID [1]: Enter the database service name:ORCL Enter 1 if you want to verify/install Oracle REST Data Services schema or 2 to skip this step [1]:1 Enter the database password for ORDS_PUBLIC_USER: Confirm password: Requires to login with administrator privileges to verify Oracle REST Data Services schema. Enter the administrator username:dataadmin Enter the database password for dataadmin: Confirm password: Connecting to database user: dataadmin url: jdbc:oracle:thin:@//dataadmin.cwt1dgu2zxag.ap-southeast-1.rds.amazonaws.com:1521/ORCL Retrieving information. Enter the default tablespace for ORDS_METADATA [SYSAUX]: Enter the temporary tablespace for ORDS_METADATA [TEMP]: Enter the default tablespace for ORDS_PUBLIC_USER [USERS]: Enter the temporary tablespace for ORDS_PUBLIC_USER [TEMP]: Enter 1 if you want to use PL/SQL Gateway or 2 to skip this step. If using Oracle Application Express or migrating from mod_plsql then you must enter 1 [1]: Enter the PL/SQL Gateway database user name [APEX_PUBLIC_USER]: Enter the database password for APEX_PUBLIC_USER: Confirm password: Enter 1 to specify passwords for Application Express RESTful Services database users (APEX_LISTENER, APEX_REST_PUBLIC_USER) or 2 to skip this step [1]: Enter the database password for APEX_LISTENER: Confirm password: Enter the database password for APEX_REST_PUBLIC_USER: Confirm password: Enter a number to select a feature to enable [1] SQL Developer Web [2] REST Enabled SQL [3] None [1]:1 2022-03-16T05:35:15.021Z INFO reloaded pools: [|dataadmin||, |dataadmin|al|, |dataadmin|rt|, |dataadmin|pu|] Installing Oracle REST Data Services version 19.4.6.r1421859 ... Log file written to C:\Users\datablogsadmin\ords_install_core_2022-03-16_133515_00223.log ... Verified database prerequisites ... Created Oracle REST Data Services proxy user ... Created Oracle REST Data Services schema ... Granted privileges to Oracle REST Data Services ... Created Oracle REST Data Services database objects ... Log file written to C:\Users\datablogsadmin\ords_install_datamodel_2022-03-16_133527_00932.log ... Log file written to C:\Users\datablogsadmin\ords_install_apex_2022-03-16_133530_00191.log Completed installation for Oracle REST Data Services version 19.4.6.r1421859. Elapsed time: 00:00:17.247
Step 7 :
Once installed ORDS , if you get any errors on ORDS users . Run below command in SQL PLUS
ALTER USER ORDS_PUBLIC_USER account unlock IDENTIFIED BY Admin123;
ALTER USER ORDS_METADATA account unlock IDENTIFIED BY Admin123;
Step 8 :
Start the ORDS Service
java -jar ords.war

Step 9 :
If you need to map your ords link with multiple schemas , its must have URL mapping . To avoid confusion to access multiple workspaces
D:\ords>java -jar ords.war map-url --workspace-id ss --type base-path /datablogs01 dataadmin

Its all completed , if you have any issues and doubts please contact us
Authors : 👷 Krishna and 👷 Selvackp