We love MongoDB for extraordinary features as per business perspective
Lets come to our Blog Discussion , Only in PaaS Environments we have features like DNS endpoints for database easily connect with primary or secondary at any single point of failure
Mongo Atlas Providing all the features but small scale customers still using MongoDB with Virtual Machines or EC2 Instances . To handle point of failures in primary we can use DNS Seed List Connection Format in mongoDB . We will discuss in detail how to we configure this in AWS Cloud
What is seed list ?
Seed list can be list of hosts and ports in DNS Entries . Using DNS we can configure available mongoDB servers in under one hood . When client connects to an common DNS , its also knows replica set members available in seed list . Single SRV identifies all the nodes associated with the cluster . Like Below ,
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false" Percona Server for MongoDB shell version v4.4.13-13 connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=false

Environment Setup :
For Testing Purpose , We have launched 3 Private Subnet Servers and 1 Public Subnet Server to use like Bastion . Create One Private Hosted Zone for DNS and Installed Percona Server for MongoDB 4.4.13 then configured Replication in it
AWS EC2 Servers ,

Route 53 Hosted Zone ,

Creating A Records :
We have launched private subnet instances , so we required to create A Records for private IP's . If Public IPv4 DNS available we can create CNAME Records
A Records Created for db1 server ,
Inside the datamongo.com hosted Zone , Just Click Create Record

Same like we need to create A Records for other two nodes

Verify the A Records ,
root@ip-172-31-95-215:~# dig db1.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db1.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 13639 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db1.datamongo.com. IN A ;; ANSWER SECTION: db1.datamongo.com. 10 IN A 172.31.85.180 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 11:58:09 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~# dig db2.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db2.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9496 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db2.datamongo.com. IN A ;; ANSWER SECTION: db2.datamongo.com. 300 IN A 172.31.83.127 ;; Query time: 3 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 12:06:28 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~# dig db3.datamongo.com ; <<>> DiG 9.11.3-1ubuntu1.17-Ubuntu <<>> db3.datamongo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46401 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;db3.datamongo.com. IN A ;; ANSWER SECTION: db3.datamongo.com. 300 IN A 172.31.86.8 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Tue Mar 29 12:06:33 UTC 2022 ;; MSG SIZE rcvd: 62 root@ip-172-31-95-215:~#
Creating SRV and TXT Records :
As like Atlas , Once we have the A Records for MongoDB Nodes , we can able to create SRV Records
Again Inside the datamongo.com hosted Zone , Just Click Create Record

Once its created , again click create record and create TXT records


Reading SRV and TXT Records :
We can use nslookup and verify the configured DNS Seeding ,
root@ip-172-31-95-215:~# nslookup > set type=SRV > _mongodb._tcp.db.datamongo.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: _mongodb._tcp.db.datamongo.com service = 0 0 27717 db2.datamongo.com. _mongodb._tcp.db.datamongo.com service = 0 0 27717 db3.datamongo.com. _mongodb._tcp.db.datamongo.com service = 0 0 27717 db1.datamongo.com. Authoritative answers can be found from: > set type=TXT > db.datamongo.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: db.datamongo.com text = "authSource=admin&replicaSet=db-replication" Authoritative answers can be found from:
Verify Connectivity :
Its all done , We can verify the connectivity with DNS Seed List Connection format ,
By Default , it will connect with ssl true , but we have configured mongodb without SSL . If you required to configure with SSL please refer our blog and configure DNS Seeding with help of this blog
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false"
Percona Server for MongoDB shell version v4.4.13-13
connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=false
Implicit session: session { "id" : UUID("ee74effc-92c7-4189-9e97-017afb4b4ad4") }
Percona Server for MongoDB server version: v4.4.13-13
---
The server generated these startup warnings when booting:
2022-03-29T11:32:47.133+00:00: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine. See http://dochub.mongodb.org/core/prodnotes-filesystem
---
db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;
172.31.83.127:27717
db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;
PRIMARY
db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).name;
172.31.85.180:27717
db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).stateStr;
SECONDARYCurrently 172.31.83.127 is the primary server and 172.31.85.180 is secondary , to test connection we have stopped the primary server (172.31.83.127) in AWS console
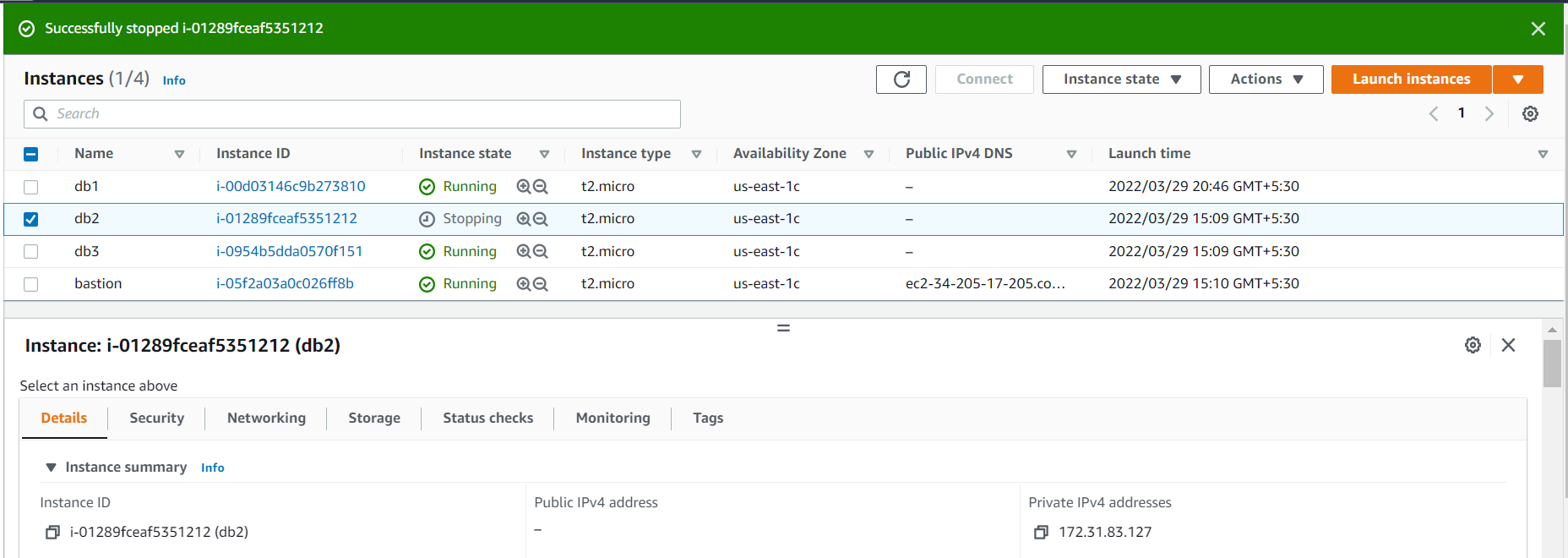
after stopping primary server (172.31.83.127) , mongodb failover happened to to 172.31.85.180 . Its verified without disconnecting the mongo shell
root@ip-172-31-86-8:~# mongo "mongodb+srv://superuser:zU2iU9pF7mO7rZ4z@db.datamongo.com/?authSource=admin&readPreference=primary&ssl=false"Percona Server for MongoDB shell version v4.4.13-13connecting to: mongodb://db1.datamongo.com:27717,db3.datamongo.com:27717,db2.datamongo.com:27717/?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&readPreference=primary&replicaSet=db-replication&ssl=falseImplicit session: session { "id" : UUID("ee74effc-92c7-4189-9e97-017afb4b4ad4") }Percona Server for MongoDB server version: v4.4.13-13---The server generated these startup warnings when booting:2022-03-29T11:32:47.133+00:00: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine. See http://dochub.mongodb.org/core/prodnotes-filesystem---db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;172.31.83.127:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;PRIMARYdb-replication:PRIMARY> rs.status().members.find(r=>r.state===2).name;172.31.85.180:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===2).stateStr;SECONDARYdb-replication:PRIMARY> rs.status().members.find(r=>r.state===1).name;172.31.85.180:27717db-replication:PRIMARY> rs.status().members.find(r=>r.state===1).stateStr;PRIMARY
Its working as expected and we have no worries if anything happens on mongoDB primary node in Cloud IaaS as Well !!!
Please contact us if any queries and concerns , we are always happy to help !!!




































